How to create and integrate a Hugging Face Inference Endpoint
Hugging Face is one of the most, if not the most important Open Source Communities, in the scope of Machine Learning and AI technologies.
It is not only a huge hub of models, datasets, and transformers, but also an environment where users can deploy, test, and productize AI models or pipelines.
Hugging Face allows users to implement and deploy models, transformers, pipelines, etc, in two different ways:
- Spaces Based on Github repos, users can implement their models here and deploy it as an app for free (it's also possible to pay for additional resources). This kind of deployment is for demo/fast development purposes, so it is not ready for production.
- Inference Endpoints. With Inference Endpoints a user or organization is able to deploy a model into production in a cloud provider in a completely transparent way. Hugging Face will take care of deploying the necessary containers, securitization, auto scaling, etc.
In this tutorial we will show you how to deploy your models and pipelines as Inference Endpoints, and how to publish them in Nevermined App, so you can safely share and monetize your AI model.
Requirements
- A Hugging Face Account
- Payment Method added. Inference Endpoints are not free. We will show you how to keep the cost pretty low so you can test it without spending too much money.
- Generate a token for your account with Read permissions.
Deploy a Hugging Face model
You can deploy any model available in Hugging Face Hub in a really straightforward way. This document from Hugging Face's documentation shows how to deploy a model from a repository.
In this tutorial we want to show you how to implement and deploy a more complex scenario, where you are not deploying an already built model, but a more elaborated process.
Implement and deploy your own AI Model
Through the next sections you will learn how to implement a custom AI model or process, deploy it as an Inference Endpoint and publish it in Nevermined App.
Create a new Model repository
In order to implement a custom model you have to create a new model repository. You can work locally in your implementation and use git to create and synchronize in Hugging Face, as it's explained in Hugging Face Documentation. In this document you will find different examples of custom models.
Also you can manually create this model repository and add/edit the files using the UI. For the sake of simplicity we are doing this in this tutorial.
To create this repository you just need to use the button New you can find in the main page of your Hugging Face profile (or your organization profile)
Once the model repository is created you can use the Add button to create and commit new files in the repository. Also you have the possibility to edit the files as many times as you need.
You will typically need a handler.py and a requirements.txt file.
Of course creating and editing the files directly in the repo is not the best way to implement your custom model because there is no way to test it before deploying the model as an Inference Endpoint.
Implementing a simple example with Haystack
As we mentioned, in the Hugging Face documentation you can find multiple examples about how to expose your own model using custom Inference Endpoints. For our example we will take a different approach, to show you that there are more possibilities than "just" use a model.
In this case we are going to use Haystack to build an InMemory store where we will index a document related to DeSci DAOs, and using roberta-base-squad2-distilled we can implement a Q&A service using the documents stored.
The first step is to add the needed dependencies using the requirements.txt file:
farm-haystack==1.19.0
farm-haystack[inference]==1.19.0
validators==0.21.1
Next we need to implement an EndpointHandler class in a handler.py file. This class will contain two methods, init, where we will place all the code that will be executed when the endpoint is starting (so it will be executed only once), and call, that handles the execution calls.
In the init method we will place all the code to initialize Haystack and to read and index the file with the DeSci DAOs information. In the call method we read the payload of the call to get the question, and we call the Haystack pipeline to get an answer.
import os
from haystack.utils import fetch_archive_from_http, clean_wiki_text, convert_files_to_docs
from haystack.schema import Answer
from haystack.document_stores import InMemoryDocumentStore
from haystack.pipelines import ExtractiveQAPipeline
from haystack.nodes import FARMReader, TfidfRetriever
import logging
import json
os.environ['TOKENIZERS_PARALLELISM'] ="false"
#Haystack Components
def start_haystack():
document_store = InMemoryDocumentStore()
load_and_write_data(document_store)
retriever = TfidfRetriever(document_store=document_store)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2-distilled", use_gpu=True)
pipeline = ExtractiveQAPipeline(reader, retriever)
return pipeline
def load_and_write_data(document_store):
# Get the absolute path of the script
script_path = os.path.realpath(__file__)
# Get the script directory
script_dir = os.path.dirname(script_path)
doc_dir = script_dir + "/dao_data"
print("Loading data ...")
docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)
document_store.write_documents(docs)
class EndpointHandler():
def __init__(self, path=""):
# load the optimized model
self.pipeline = start_haystack()
def __call__(self, data):
inputs = data.pop("inputs", None)
question = inputs.pop("question", None)
if question is not None:
prediction = self.pipeline.run(query=question, params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 5}})
else:
return {}
# postprocess the prediction
response = { "answer": prediction['answers'][0].answer}
return json.dumps(response)
And that's it. We can now deploy this process as an Inference Endpoint. But remember, in a real scenario you should implement and test your model/process in your local environment to check that everything works correctly.
Expose the custom Model as Inference Endpoint
The next step is to publish your model as an Inference Endpoint. Remember, you need to add a Payment Method to be able to use this Hugging Face's capability.
You can access Inference Endpoints here. In the main screen you can see the endpoints you have already deployed, and a New endpoint button to create a new one.
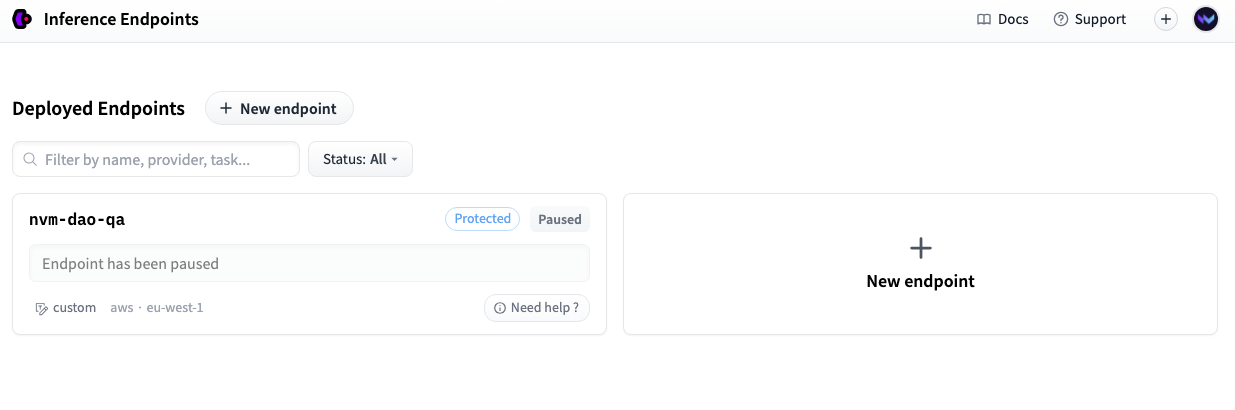
In the New Endpoint form, you have to introduce the name of the repository where you have implemented your model. Also you need to choose the Cloud Provider (you can leave the default one).
You can pick a small Instance type, instead of the medium one, to keep the cost low (You can see the estimated cost per hour at the bottom of the screen). Take into account that this also implies that the execution time will be longer.
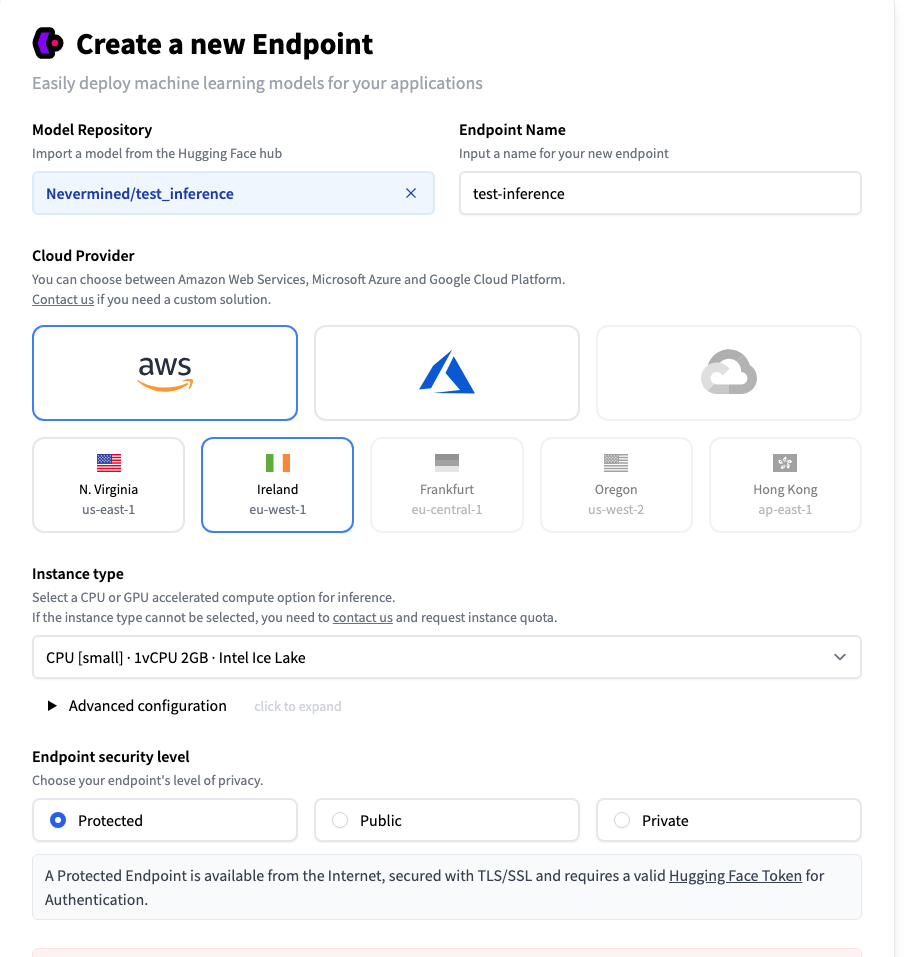
In the Advanced Configuration section you can find some useful configuration. For instance, you can enable the Automatic Scale-to-Zero option so the endpoint will be effectively paused where there is no activity (You can pause and resume your endpoint manually as well). The time the endpoint is paused won't be billed.
Once you finish setting all the configuration, click on the Create Endpoint button, and the Inference Endpoint will be initialized.
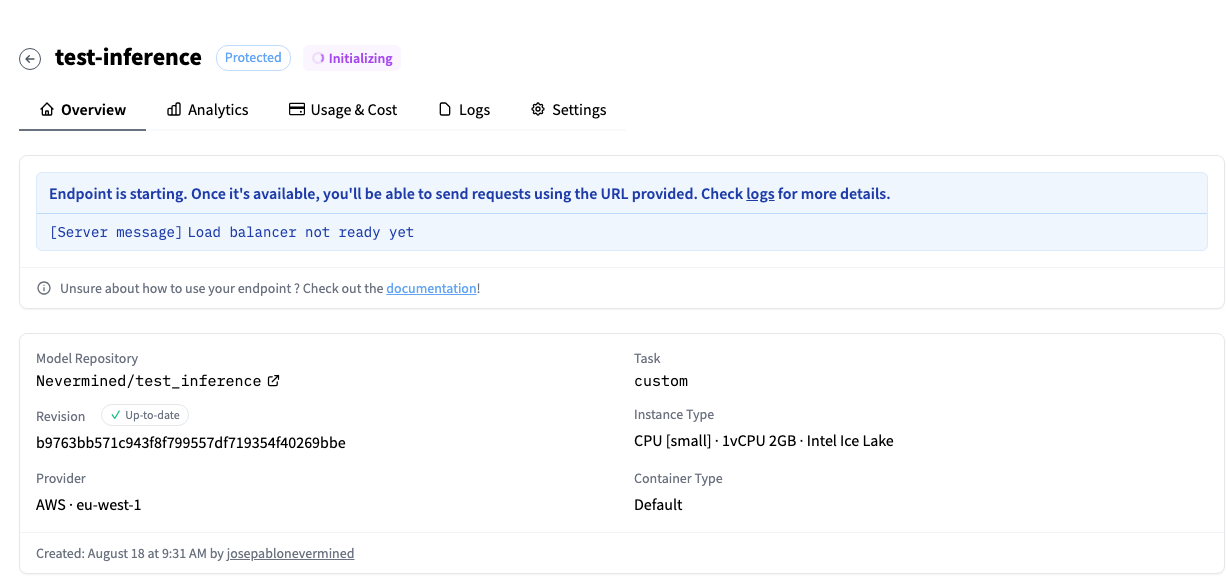
After a few minutes you will see your Inference Endpoint running and the screen will show you the URL where it is located.
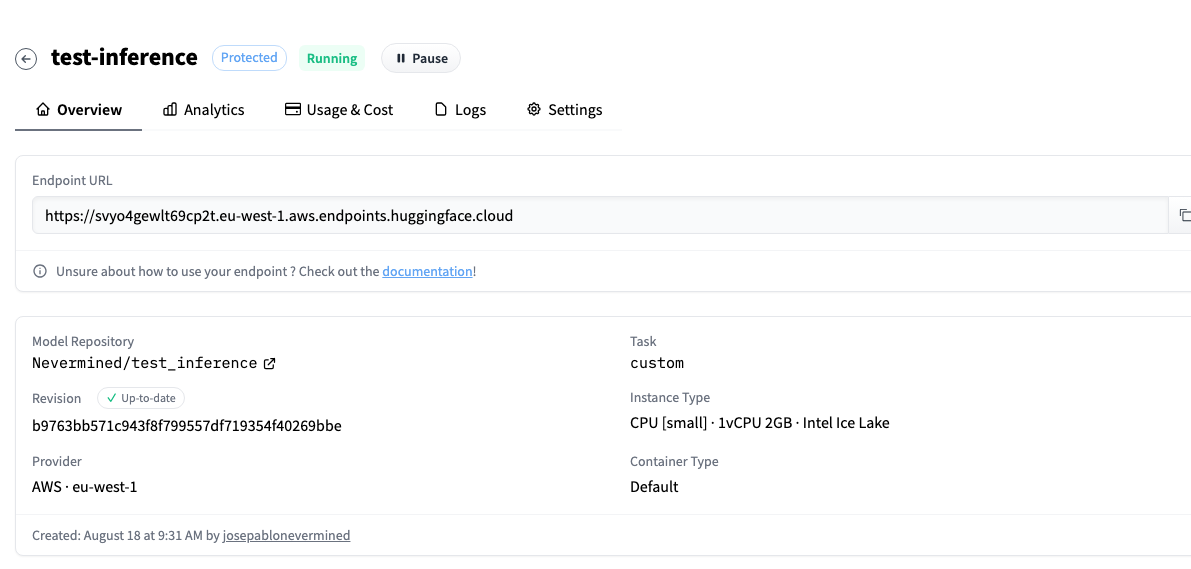
In the Settings menu you can change the configuration of the Inference Endpoint, or update it to the latest version in your repository.
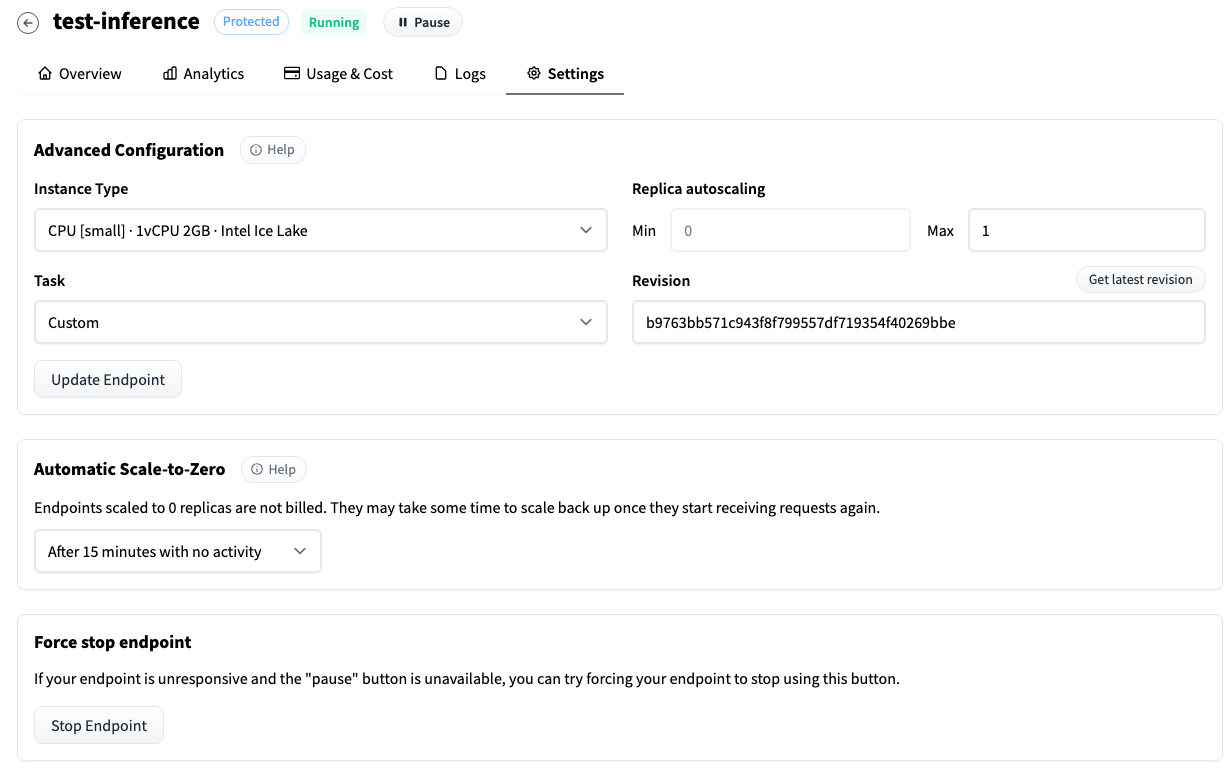
Testing the Inference Endpoint
To test the Inference Endpoint you just need the URL and your Read Token.
export HF_TOKEN="api_orgweRt....srbCQpQ"
curl https://clmdl67ebofnkfxk.eu-west-1.aws.endpoints.huggingface.cloud \
-X POST \
-d '{"inputs":{"question":"What is VitaDAO?"}}' \
-H "Authorization: Bearer $HF_TOKEN" \
-H "Content-Type: application/json"
If the execution of the endpoint takes around (or over) a minute, we recommend you change the settings of the Instance Type, for instance from small to medium.
If you have deployed the Inference endpoint under an organization, any user who belongs to the organization will be able to access the endpoint using their own Read Tokens.
Publish the Inference Endpoint in Nevermined
Once you have implemented, deployed, and protected your own AI model or pipeline in Hugging Face, you can share it with the Community in a safe way, and even monetize it, if you want, using a Nevermined Pricing Plan.
In order to test and learn how you can use Nevermined App, we provide a testing environment where you can try the different features provided by Nevermined.
You can access this test version of Nevermined App here
Before you register your Service
We recommend you take a look at the different guides and tutorials we have about Nevermined App
The next step is to create a brand new Pricing Plan
You will register your AI Service associated with this Subscription you are about to create. The process to create a new Subscription is pretty straightforward, but here you can find some help to guide you.
Registering the AI Model
So now that you have all set up and you have created a Pricing Plan, you can create a Web Service Agent to register your AI Model in Nevermined App.
You can find a complete guide to register your service here
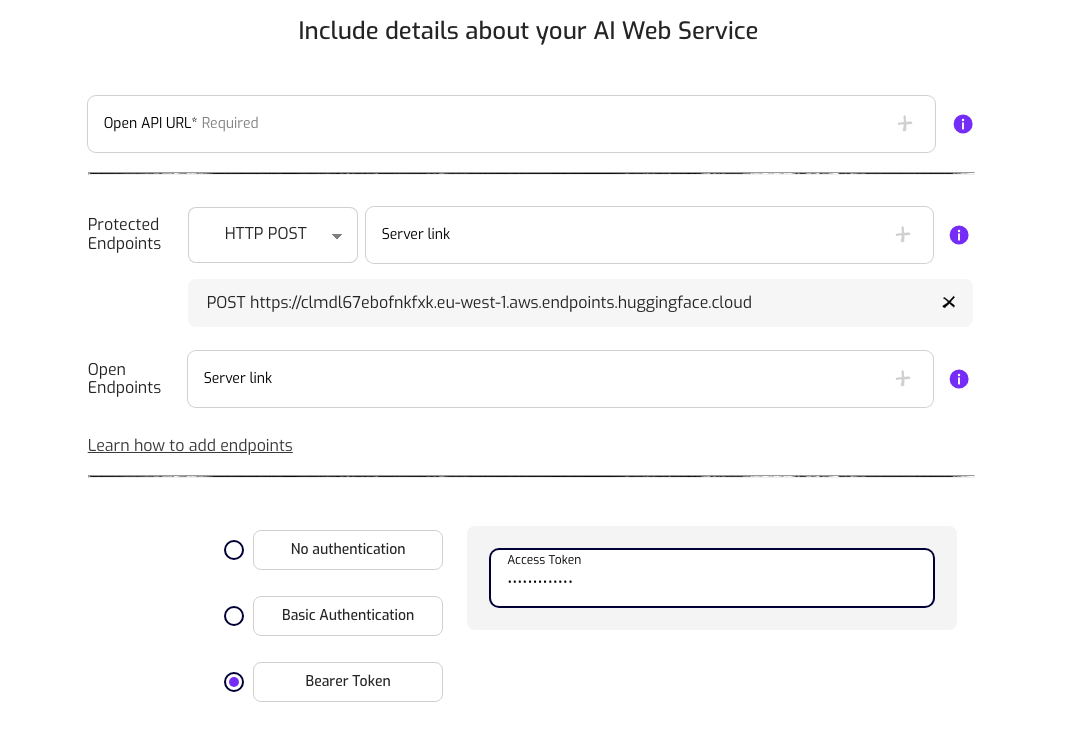
In the details step you need to add the endpoint. As the Inference Endpoint does not generate any OpenAPI document, we need to do it manually.
Add the Inference Endpoint URL as a HTTP POST Protected Method.
Select Bearer Token and add a Hugging Face Token with Read Permissions. This token will be sent and stored encrypted, so no one will be able to access it.
Make sure you provide enough information about your service in the Description and Integration fields to allow the user to understand the purpose of your service and how they can use it.
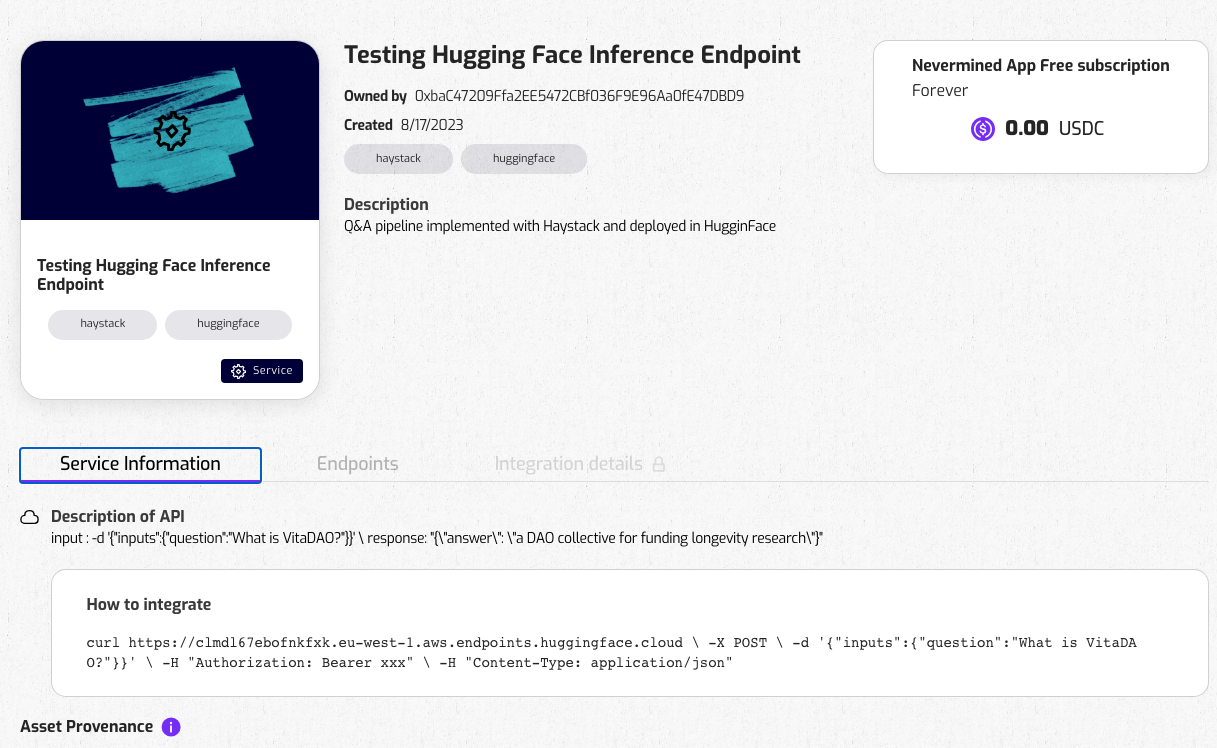
Access to the details of the Service
When the process is finished, you will be able to access the details of your new Service Agent (you can also access anytime using the "My Agents" menu on the App). In the Service details you can access the description of the endpoints.
Consuming your AI Model�
Every user that has purchased your Subscription will be able to use your AI Model through Nevermined. In this guide you can find how users can integrate your service.
Examples
Using the service through Nevermined Proxy URL is really straightforward. You need to use the Proxy URL instead of the actual URL of your service, adding the specific endpoint you want to call and the parameters defined in that endpoint, and include the Authorization Header with the JWT.
For instance:
export NVM_TOKEN="eyJhbGciOiJkaXIiLCJlbmMiOiJBMTI4Q0JDLUhTMjU2In0..EW-BsszuYJLLuBylm6VPvw.zlGJQcCRjjG_m....srbCQpQ"
curl -H "Authorization: $NVM_TOKEN" -X POST "https://3dqf53c6wn5sd5crq1n0bzh92cr09kaevh16io0pbefn57kbcj.proxy.testing.nevermined.app" \
--header 'content-type: application/json' \
--data '{"inputs":{"question":"What is VitaDAO?"}}'